


AI21推出了全球首个生产级Mamba模型——Jamba,这一模型引领创新,采用了独特的SSM-Transformer架构,并配备了庞大的52B参数,其中12B参数在模型生成时处于活跃状态。Jamba融合了Joint Attention与Mamba两大技术,支持高达256K的上下文长度,同时,在单个A10080GB上,其最大上下文容纳能力达到了140K。相较于Mixtral8x7B,Jamba在长上下文处理上的吞吐量实现了三倍的提升。
AI21发布世界首个Mamba的生产级模型Jamba 支持256K上下文长度
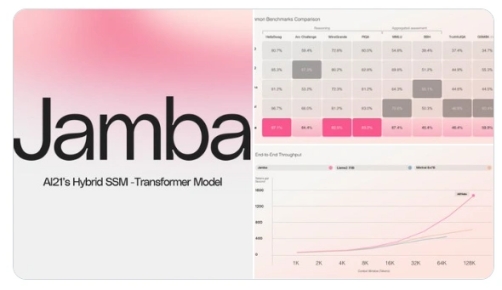
Jamba代表了模型设计领域的一大进步。它通过结合Mamba的结构化状态空间(SSM)技术与传统的Transformer架构元素,打破了纯SSM模型的限制。Mamba作为一种结构化状态空间模型,特别擅长捕捉和处理随时间变化的数据,尤其是序列数据,如文本或时间序列。SSM模型在处理长序列数据时表现出色,但在应对复杂模式和依赖关系时可能稍显不足。
另一方面,Transformer架构已成为近年来AI领域,特别是自然语言处理(NLP)任务中的佼佼者。它能够出色地理解和处理语言数据,捕捉长距离依赖,但在处理长序列数据时可能面临计算和内存方面的挑战。
Jamba模型的独特之处在于它将Mamba的SSM技术与Transformer架构相结合,从而实现了两者的优势互补。这种结合使得Jamba不仅能够高效处理长序列数据(继承自Mamba),还能保持对复杂语言模式和依赖关系的深刻理解(得益于Transformer)。因此,在处理涉及大量文本理解和复杂依赖关系的任务时,Jamba模型能够同时保证高效率、高性能和高精度。














