


材料科学家发现新材料通常需要耗费很长时间。他们需要进行大量的数字运算、属性研究并运行大量的模拟。
与其他计算方法或反复试验相比,AI 可以更有效地探索化学空间,加速材料的发现和设计。但出现的一个障碍是缺乏公开数据和开放的预训练模型。
近日,Meta 公司推出一个名为「Open Materials 2024」(OMat24)的大型开放数据集和配套的预训练模型,旨在彻底改变 AI 驱动的材料发现。整个系统都是开源的,解决了材料发现中最令人头疼的问题之一:没有足够优质、可访问的数据。
OMat24 包含超 1.1 亿个结构密度泛函理论 (DFT) 计算,重点关注结构和成分多样性,成为该领域最大的公开数据集之一。
研究人员还展示了 EquiformerV2 模型,这是一种在 OMat24 数据集上训练的最先进的图神经网络 (GNN),在 Matbench Discovery 排行榜上实现了最先进的性能,能够预测基态稳定性和形成能,F1得分高于 0.9,精度达 20 meV/atom。
剑桥大学分子建模教授 Gábor Csányi 表示(没有参与该研究),「Meta 决定公开其数据集比 AI 模型本身更重要。这与谷歌和微软等形成了鲜明对比,他们最近也发布了看似具有竞争力的模型,但这些模型是保密的数据集上进行训练的。」
新材料的发现对于众多应用都至关重要。从应对气候变化到下一代计算硬件的进步。可能材料的搜索空间非常巨大,现有的计算和实验方法在有效探索广阔的化学空间方面存在很大局限。
虽然 AI 已成为材料发现的强大工具,但缺乏公开数据和开放的预训练模型。密度泛函理论 (DFT) 计算对于研究材料的稳定性和性质至关重要,但计算成本高昂,限制了其在探索大型材料搜索空间中的实用性。
Meta FAIR 研究人员推出的 Open Materials 2024 (OMat24) 数据集和模型,旨在进一步推动 AI 和材料科学的快速发展。
OMat24 数据集
OMat24 数据集由 DFT 单点计算、结构弛豫和多种无机块体材料的分子动力学组合而成。总共计算了约 1.18 亿个标有总能量、力和晶胞(cell)应力的结构。每个结构的原子数范围为 1 到 100 个原子,大多数结构有 20 个或更少的原子。
这些结构是使用玻尔兹曼采样、从头算分子动力学 (AIMD) 和扰动结构的弛豫(relaxation of rattled structures)等技术生成的。该数据集强调非平衡结构,确保在 OMat24 上训练的模型非常适合动力学和远离平衡的特性。
OMat24 包括物理上重要的非平衡结构,具有广泛的能量、力和应力分布,以及显著的成分多样性。
OMat24 数据集建立在其他公共数据集之上,例如 MPtrj、Materials Project 和 Alexandria,其中包含平衡或近平衡构型。
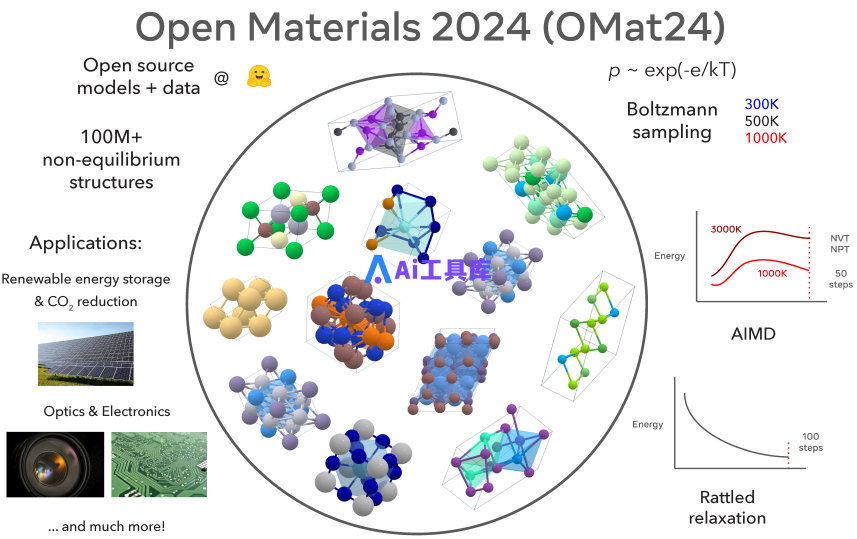
图示:OMat24 数据集生成、应用领域和采样策略概述。
OMat24 的元素分布基本覆盖了元素周期表。该数据集涵盖了与无机材料发现相关的大多数元素。由于氧化物在大多数开放数据集中都较为丰富,因此与其他元素相比,氧化物的代表性略高。
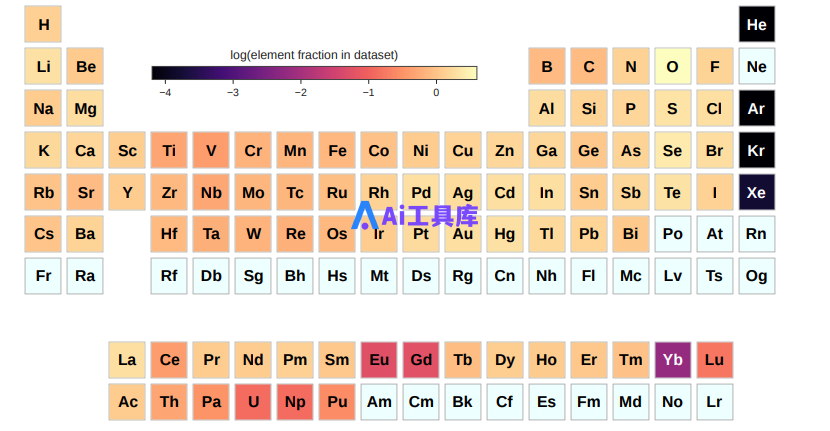
图示:OMat24 数据集中元素的分布。
OMat24 模型和训练策略
研究人员探索了模型大小、辅助降噪目标和微调对一系列数据集(包括 OMat24、MPtraj 和 Alexandria)性能的影响。
研究人员利用 OMat24 数据集以及 MPtrj 和 Alexandria 数据集来训练 GNN。由于 Alexandria 数据集和用于测试的 WBM 数据集中存在类似的结构,研究人员对 Alexandria 数据集进行了子采样以进行训练,以确保训练数据集和测试数据集之间没有泄漏。通过删除所有与 WBM 初始结构和弛豫结构中的结构相匹配的结构,创建了 Alexandria 的新子集 (sAlexandria)。
接下来,通过删除所有能量 > 0 eV、力范数 > 50 eV/Å 和应力 > 80 GPa 的结构来缩小数据集的大小。
最后,只对剩余轨迹中能量差大于 10 meV/atom 的结构进行采样。用于训练和验证的结果数据集分别有 1000 万和 50 万个结构。
对于模型架构,研究人员仅关注 EquiformerV2,它是目前在 OC20 、OC22 和 ODAC23 排行榜上表现最好的模型。对于模型训练,研究人员探索了三种策略:
- EquiformerV2 模型仅在 OMat24 数据集上训练,带有和不带有去噪增强目标。这些模型具有最强的物理意义,因为它们仅适合包含与旧版 Materials Project 设置相关的底层伪势重要更新的数据集。
- EquiformerV2 模型仅在 MPtrj 数据集上训练,带有和不带有去噪增强目标,可用于直接与 Matbench Discovery 排行榜进行比较(表示为「兼容」模型)。
- 来自 (1) 或 OC20 检查点的 EquiformerV2 模型在 MPtrj 或 sAlexandria 数据集上进一步微调,从而成为 Matbench Discovery 排行榜上表现最好的模型(表示为「不兼容」)。
总之,在 MPtrj 上从头训练的 EquiformerV2 模型是 MatBench Discovery 上「兼容」模型中最先进的,MAE 高达 35 meV/atom。
在 Matbench Discovery 基准上进行评估时,使用 OMat24 训练的 EquiformerV2 模型的 F1 得分为 0.916,平均绝对误差 (MAE) 为 20 meV/atom,为预测材料稳定性设定了新的基准。

与同类别的其他模型相比,这些结果明显更好,凸显了在 OMat24 等大型多样化数据集上进行预训练的优势。此外,仅在 MPtraj 数据集(相对较小的数据集)上训练的模型也表现良好,这要归功于有效的数据增强策略,例如非平衡结构去噪 (DeNS)。结果表明,OMat24 预训练模型在准确性方面优于传统模型,尤其是对于非平衡构型。
OMat24 数据集和相应模型的推出,代表了 AI 辅助材料科学的重大飞跃。这些模型能够以高精度预测关键属性(例如形成能),因此对于加速材料发现非常有用。重要的是,此开源版本允许研究界在现有基础上继续发展,进一步增强 AI 在新材料发现中的作用。














